Title: Extracting the main trend in a data set: The Sequencer algorithm
Author(s) and year: Dalya Baron and Brice Ménard (2021)
Status: Published in The Astrophysical Journal, open access: HTML, PDF.
Editor’s note: This post is republished with permission from MathStatBites to demonstrate the Bites concept. For more information about Bites articles and how to contribute to DataScienceBites, see our notes for contributors.
Large volumes of data are pouring in every day from scientific experiments like CERN and the Sloan Digital Sky Survey. Data is coming in so fast that researchers struggle to keep pace with the analysis and are increasingly developing automated analysis methods to aid in this herculean task. As a first step, it is now commonplace to perform dimension reduction in order to reduce a large number of measurements to a set of key values that are easier to visualize and interpret.
When working on the cutting edge, another problem scientists often face is that “we don’t know what we don’t know”. For this reason, we often want to simply ask the data, “What is interesting about you?” This is the realm of “unsupervised” methods, where the data itself drives the analysis, with little to no guidance or human labeling of the data.
Many physical processes depend continuously on some driving parameter. For example, the evaporation rate of water increases with temperature. We call these continuous variations in datasets “trends”. Describing a dataset by a single trend reduces it to one dimension - an ordered list. Finding such a trend within a high-dimensional dataset is the aim of a method called “The Sequencer” introduced by Baron and Ménard.
1 Key insight: A tree
The key insight of Baron and Ménard was to relate trends in data to an object from graph theory called a minimum spanning tree. Given a measure of distance between two data points, for example the usual (Euclidean) distance between two points, we can visualize a dataset as a graph. This graph consists of a node (a dot) for each data point. These nodes are then connected by an edge (a line), labeled by the distance between the two data points. The minimum spanning tree is a reduction of this graph to include only enough of the smallest distance edges so that no node is isolated.
What Baron and Ménard realized is that datasets that are “trendy” have elongated and narrow minimum spanning trees. As shown in Figure 1, a totally random dataset results in a graph with many branches while a perfect sequence results in a perfect linear graph. Then, they use connectivity of the nodes in the minimum spanning tree to return an ordering of the data that follows the main trend in the dataset. However, a sequence is all you get. It is up to us to understand and interpret what this trend represents.
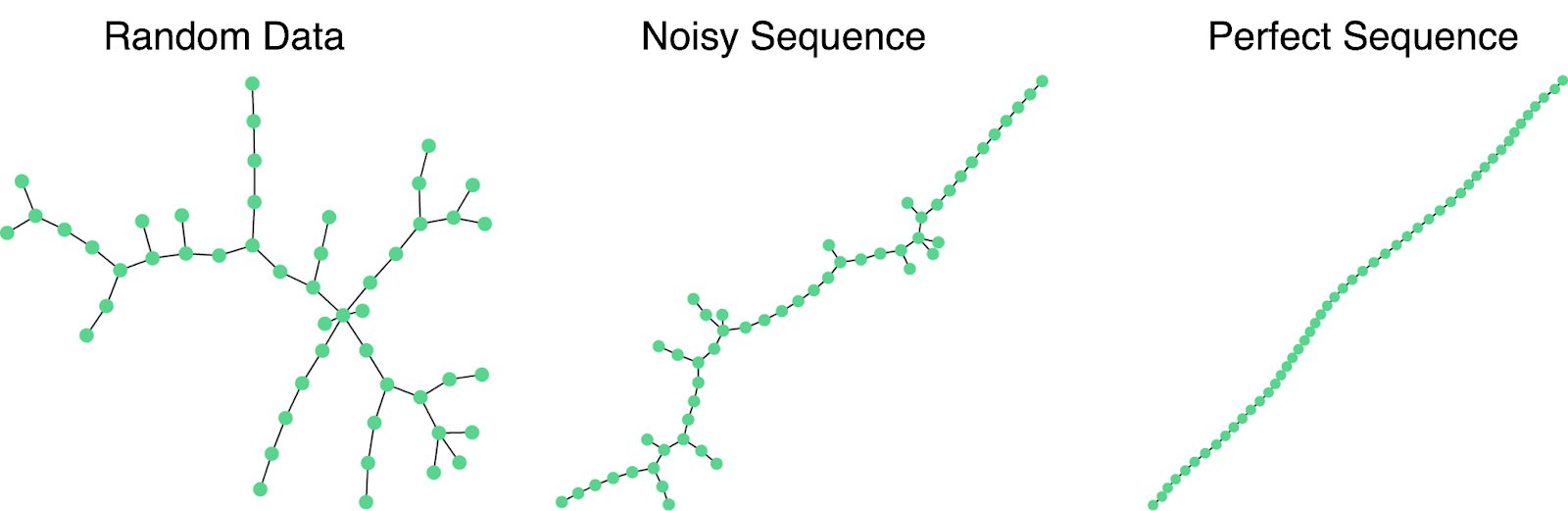
Figure 1: Examples demonstrating that data with stronger trends have more narrow and elongated minimum spanning trees. Adapted from Baron and Ménard (2021), Figure 1. Figure used under CC BY 4.0.
Sometimes, the ordering of observations within a data point matters, like in time series data. Measurements taken close in time are more likely to be correlated than measurements taken after a long time delay. Baron and Ménard were careful to include a measure of distance that takes this ordering into account, unlike our usual notion of distance. They argue that this gives them an edge over other common dimension reduction techniques such as t-SNE and UMAP, and even go so far as to use The Sequencer to optimize the hyperparameters used by these other methods!
2 When does it fail?
It is important to acknowledge that no statistical or machine-learning tool is a cure-all. And, the authors themselves are quick to point out several limitations that can hinder the application of their method. The Sequencer can struggle when the data has a large dynamic range, a variety of signal strengths relative to noise, or there are multiple trends present in the data. In each case, Baron and Ménard propose ways to mitigate these problems, but practitioners still need to be wary when applying The Sequencer in those instances.
3 What discoveries await?
To demonstrate the power of their method, Baron and Ménard apply The Sequencer to several real datasets where a pattern was already known and show that The Sequencer recovers that pattern. Examples include ordering spectral measurements of stars by their temperature and quasars by their redshift, a measure of their distance from us on Earth.
But, what about new patterns? The team has already applied The Sequencer to mine seismographic data and discover previously unknown formations deep within the earth, at the boundary between the core and mantle. By sequencing the seismic waves, they realized that the main trend was the amplitude of diffraction off of these structures, which they were then able to localize beneath Hawaii and the Marquesas (DOI: 10.1126/science.aba8972).
For more demonstrations and discoveries, or even to upload your own data for sequencing, check out the project website. Data sleuths can also download all of the code directly from GitHub and sequence to their hearts’ content!
- About the author
- Andrew Saydjari is a graduate student in physics at Harvard researching the spatial and chemical variations of dust in the interstellar medium. He favors using interpretable statistics and large photometric and spectroscopic surveys.
- About DataScienceBites
- DataScienceBites is written by graduate students and early career researchers in data science (and related subjects) at universities throughout the world, as well as industry researchers. We publish digestible, engaging summaries of interesting new pre-print and peer-reviewed publications in the data science space, with the goal of making scientific papers more accessible. Find out how to become a contributor.