
大約四、五年前,本站
這次趁着冠病疫情閉關的契機,
答案就是「不要臉」,放手去抄襲!正所謂,無恥抄襲,所向披靡;沒臉沒皮,天下無敵。
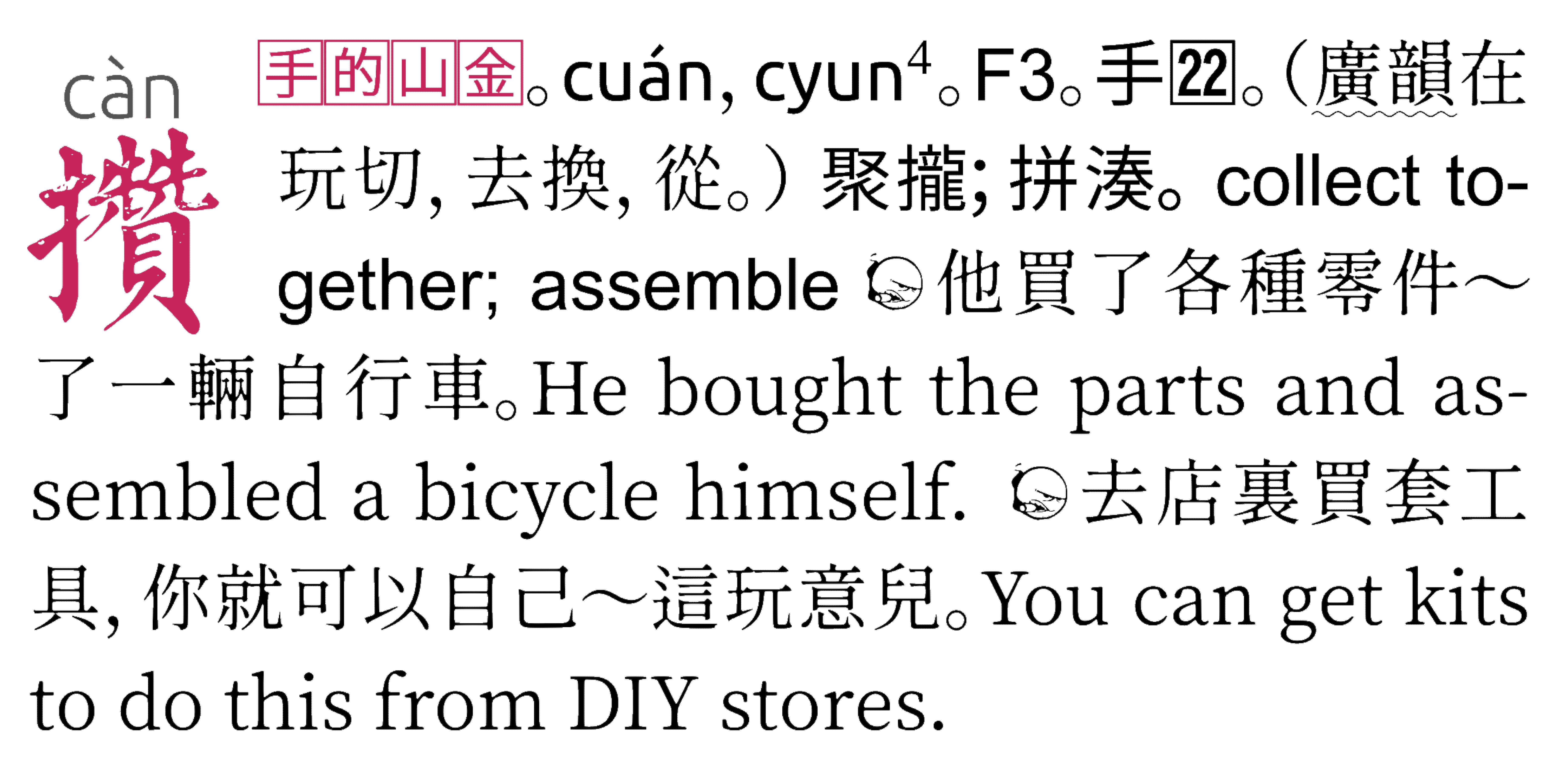
整合商、組裝廠
一人行爲之轉變,源自思想認識之轉變。思想認識之轉變,大多並非瞬間完成,而是漸進之過程。
所以,本文所展示的這份 A4 列印後兩千多頁、節本一千五百多頁的字典草稿,從頭到腳,由內而外,沒有一個字符是
下圖是草稿大致確定的直排版式效果,與《TeX 漢語字典模板》相比,並無大的調整。直排、橫排兩種版式,若要配備英語解釋,做成漢英雙解字典,則應使用橫排版式,如本文開頭圖片展示的那樣。一旦腦子活絡了,沒有什麼是不可以抄襲的:連版式設計、色彩偏好也是抄襲了《全訳漢辞海》。不過,限於技術水平,有些設計沒有抄到位。
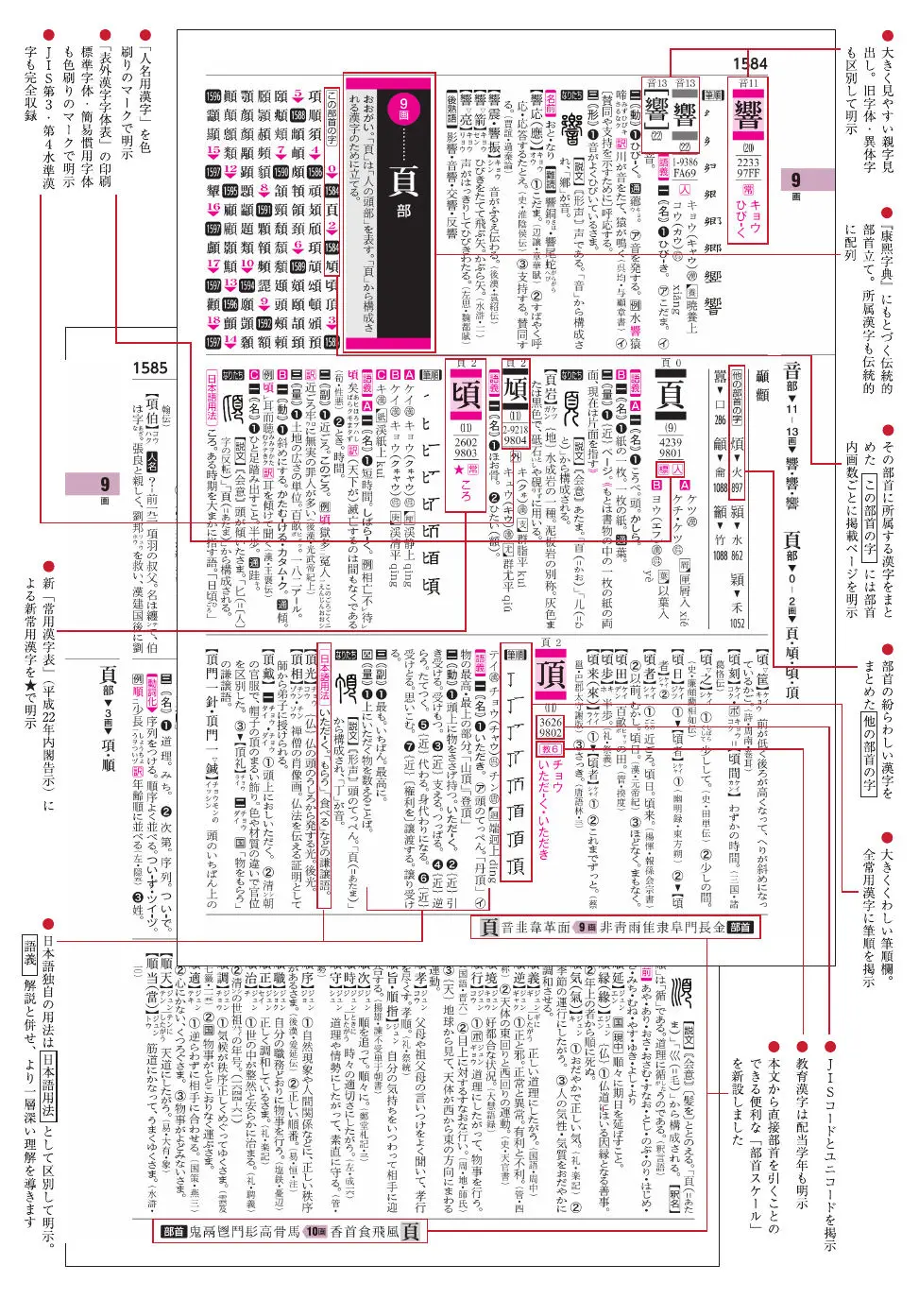
——咦?!上面這個版式設計看着挺美觀的。
——是嗎?
攢
它!

徒手攢的流程
研究這方面,研究是不可能研究的,這輩子不可能研究的。獨立編輯又不會編輯,就是偷這種東西,纔維持得了生活這樣子。我不生產字書,我只是大字書的 搬運 工,並立志做一個洋溢着企業家精神的整合商與組裝廠。
字典編輯從內容到形式,涉及方方面面,有的在其他文章中已說明。下面請依次從藍本、條目、音、形、義方面說明組裝流程。
路:到誰家去抄襲
既然厚着臉皮決定 抄襲 了,那就要對得起這巨大的成本。一般人家的字書,水平未必可靠,還不值得去抄襲呢。
先抄《重編國語辭典》
起初,站長 抄襲 的是《敎育部重編國語辭典(修訂本)》。因爲:
- 它聲稱自身的特色爲:「本典為一部歷史語言辭典,記錄中古至現代各類詞語,並大量引用古典文獻書證,字音部分則兼收現代及傳統音讀。」以淺陋的認知功力,覺得此書貫通古今,簡明清晰,如獲至寶。這不正是自己心心念念的字書的樣子嗎。
- 該字書是按照「創用CC公眾授權條款」公開上網的。「……本授權條款允許使用者重製、散布、傳輸著作(包括商業性利用),但不得修改該著作,使用時必須遵照「使用說明」之內容要求。」無侵權之虞,對受過良好知識產權法學敎育的站長來說,真是求之不得的資源。
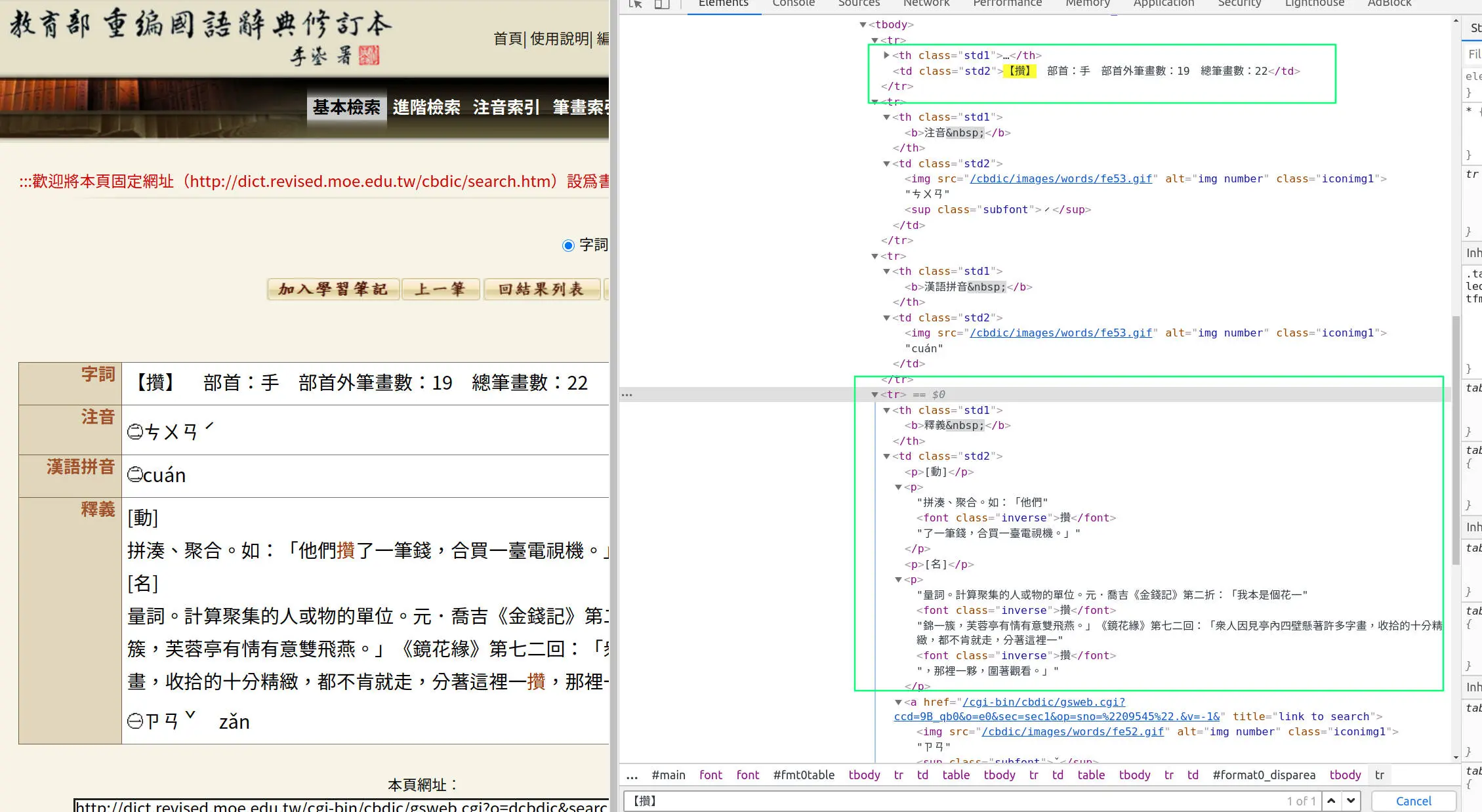
- 如下圖所示,這是網頁版式的資源,意味着文字是結構化格式化的文本,應該可以便捷地「爬取」全部文字。而且,肯定有人早已「爬取」了所有資料。
但經過站長的仔細分辨,又覺得雖然它號稱古今兼收,但就深度與廣度而言,並不十分令人滿意。苛刻地說,處理得好,是古今兼收,皆大歡喜;處理不好,便是不今不古,顧此失彼。因此,權衡成本,站長迅速轉換 抄襲 對象。
終歸《漢語大詞典》
最終又回到五年前最屬意的「藍本」——《漢語大詞典》。因爲:
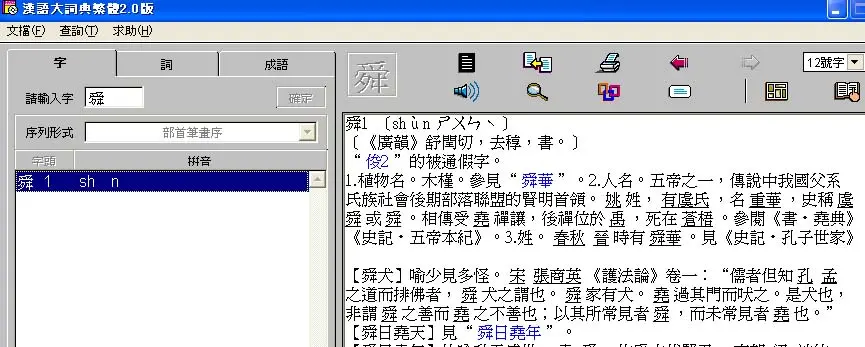
唯一的遺憾是,該字書沒有像上面那本那樣按照某種授權協議對公眾開放。提取、整合、編輯其文本內容,自然是侵權行爲。
等等,不對,臉都不要了,還顧得上侵權不侵權嗎?
攢 它!
但,全書共有十二卷,近五千萬字。顯然,這種體量是用以備查的,全部 抄襲 過來,既無必要,也不可行。所以,得有個 篩選 標準。
目:抄襲哪些內容
這主要是指確定提取哪些字頭的內容。
字頭立目
若干中型辭書的選字立目數量大同小異,大都較爲接近,維持在一萬一千個字頭左右。最後站長參考的標準是
現代計算機技術的運用,以及古典中文語料庫的建立,爲「科學」而非「主觀」地選字立目提供了良好的參考。所以,依據《四部叢刊》《四庫全書》得出的《中国古籍用字字频与分布统计分析》及字頻表也是本草稿的 篩選 標準。這個資源是在 GitHub 上開源的,但公佈者並未說明使用權限。
兩種材料整合,仍然確定了一萬一千個多個字頭。其餘的一萬九千個在字頻表內的字頭,大都是「某某字異體、某某字俗寫」之類,對本草稿的設計初心並無價值。
字頻標示
站長將這些字頭按其在字頻表的位置,分了十一個層級,每個層級一千字,並在最終版式上一起呈現。即標有「F0」的即意味着這個字在字頻表的 0~1000 範圍內,屬於最常見的字頭,其他「F1……F11」同理類推。這也便於附錄製作、提供字頭字頻索引。
音:語音怎麼抄法
站長 編輯 這本字典,原只是要 攢 出一部符合自身喜好的字書,並無任何其他的企圖。所以,語音怎麼標註,純屬隨機的玩兒法。
目前,標註了《切韻》系統的中古發音(擬音),普通話讀音、粵語讀音,這些都是直接 整合 或借力其他人的資源完成的。站長對音韻學毫無學習與研究經歷,自然無法鑑別正誤得失。
中古擬音
根據詩歌自覺與高峯階段,中古音大概最能反映大部分詩歌原本的音韻特徵。所以,爲中古漢語擬音的人很多,包括科班專家、外行專家、「民科」。在網絡上流行的擬音系統方案也有若干版本。站長最終選擇的是
放着那麼多的科班專家的方案不用,卻選用分子人類學學者的方案,主要考慮其在十年前錄製了一套完整的視頻敎程。這個方案有自己的 Rime 輸入法方案,碼表容易獲取,「借力」使用較爲便捷。這對站長這樣的音韻學 小白 而言是很友好的方案。擬音系統的作者雖是分子人類學學者,但去年在 Nature 上發表了一篇研究漢藏語系起源的論文,想必其在這方面的功力很強大。沒辦法,自己不做研究的人,又不願或沒有功力分析鑑別,只好選擇信以爲真。

字典中標註在字頭上方的,如「 攢 」,即該字的中古發音擬音。今天普通話「攢」讀平聲或上聲,但中古音爲去聲或上聲,這與《漢大》呈現的《廣韻》音系「去換」一致。
上古擬音
除此之外,在 Rime 輸入法的上古全拼輸入方案中,可以找到基於
方言土語
同理,許多母語愛好者爲 Rime 輸入法製作了不少方音土語輸入方案,碼表可獲得這些方言土語的拼音方案。如
那爲什麼標記了字頭的粵語發音呢?因爲五年前便擬標記粵音了,雖然完全聽不懂,也完全無法鑑別所依據碼表的正誤,但畢竟在粵務工, 整合 進來聊備一格。如果在滬務工, 整合 的或許是吳音碼表呢。
形:字形怎麼抄法
立目字頭的字形主要採用兩種字形。
十三經集字摹本字型
在字頻表前三千以內的字頭採用基於《十三經集字摹本》製作的顏、歐風格的字形。


內木一郎的 I.Ming
其他字頭則亦內木一郎製作的開源字體 I.Ming 呈現。如上面整頁版面示例圖的「闛」字頭。這款字型的作者是舊字形或「傳承字形」的著名擁躉,故其字形自然不符合官方規範的標準。但,開源就夠了。
說文篆體字型
如《全訳漢辞海》,某些字頭附列其說文篆體字形。如下圖所示,本草稿也曾嘗試在每個字頭後附列對應篆文字形,以北师大说文小篆或全字库说文解字呈現。但這兩款字型的製作依據不清楚,且時常會缺失字符,便暫時放棄篆體呈現。除非自己製作一款說文篆體與立目字頭一一對應,否則這個問題無解。既然由內而外無一是有「自主知識產權」的,那就沒必要熬夜研究、製作篆體字型了。

義:釋義怎麼抄法
即便僅僅提取一萬一千個字頭,文本內容體積依然極爲龐大,龐大到一般的文本編輯軟件打開整個文件便瞬間卡頓。這還只是單字字頭,還不包括字頭的組詞條目。所以,勢必要對義項與例證編輯簡化。

義項整合與歸併
《漢大》的解字是號稱貫通古今源流的。因此字頭的義項分列極其詳細,導致許多字的義項多達幾十個。這不符合本草稿編輯初心,本該學習
例證篩選與刪減
有的義項古今通用,所以某一義項的例證可能選取從《尚書》到《魯迅全集》各個時期的典型用例。這導致例證占用篇幅較大,所以本草稿索性統一只保留用例第一條(即始見書或相對早期的例證)。這可能會導致讀者無法判斷某一義項是否仍用於現代社會。不過,這讀者就小偷一人,問題也不大。
結語
上面的話,零零散散,毫無邏輯,大致展示了
讀者諸君若對此草稿 PDF 文檔有興趣,可以郵件索取。(版權所限,草稿是不可能公開傳佈的)
本文在 bilibili 以及 Youtube 附有視頻解說。
The article was recently updated on Monday, April 6, 2026, 20:00:59 by
